-
[Tensorflow Object Detection API] custom data로 재학습(retraining) 시키기 2 - 데이터 라벨링, TFRecord 파일 만들기머신러닝 2020. 5. 8. 19:58
지난번 데이터 수집하기 포스팅 이후로 생각해보니까
Tensorflow Object Detection API 설치 방법도 포스팅 해야겠구나 싶어서 다음 포스팅이 조금 늦어졌네요
혹시 아직 API 설치를 안하신 분들은 여기 참고해서 먼저 설치해주세요!
https://skkim1080.tistory.com/13?category=820062
[Tensorflow Object Detection API] 설치하기 (for window)
먼저 Python이 설치되어있어야 합니다. 설치 안하신분은 제 블로그 글 참고하세요 (중간에 customize installation말고 그냥 Install Now하시고, 밑에 Add Path 체크박스 클릭하세요.... 제가 썼지만 왜 그렇게 어..
skkim1080.tistory.com
0. 데이터 옮기기
수집한 이미지 데이터들을 object_detection>images 폴더에 옮길 것입니다.
(참고한 블로그는 따로 폴더를 생성하고 나중에 API 폴더로 옮기신 것같지만 저는 처음부터 API 폴더에 넣어서 했습니다)
데이터를 옮기기전에 우선 images 폴더안에 test폴더와 train 폴더를 만들어주세요.
그리고 이미지들을 각 폴더에 넣으면 되는데 저는 train:test=9:1 비율로 옮겼습니다.
아 그리고 저는 라벨링하기 전에 미리 png 파일들은 제거해주었습니다.
1. 데이터에 라벨링하기
데이터 수집을 마쳤으니 이제 이미지 데이터에서 detection하고 싶은 object의 위치에 boundingbox와 label을 지정해야합니다.
저는 LabelImg라는 프로그램을 사용했습니다.
① LabelImg 설치하기
> pip install labelImg * 저는 이 이후에 다시 설치를 하는 중에 오류가 발생했는데요.
혹시 pip install로 설치가 제대로 안되시는 분들은
github.com/tzutalin/labelImg 이 링크 참고해서 설치 하시면 됩니다.
코드 다운로드 하시고 installation 가이드 잘 따라가시면 됩니다.
② LabelImg 실행, dir 설정
cmd창에 labelImg라고만 입력하면 LabelImg가 실행됩니다.
> labelImg 프로그램이 실행되었다면 "Open Dir", "Change Save Dir" 버튼을 눌러 라벨링할 데이터가 있는 폴더와 라벨링 정보가 작성된 xml파일을 저장할 폴더를 설정합니다. (저는 xml파일도 이미지 파일 폴더에 저장했습니다.)

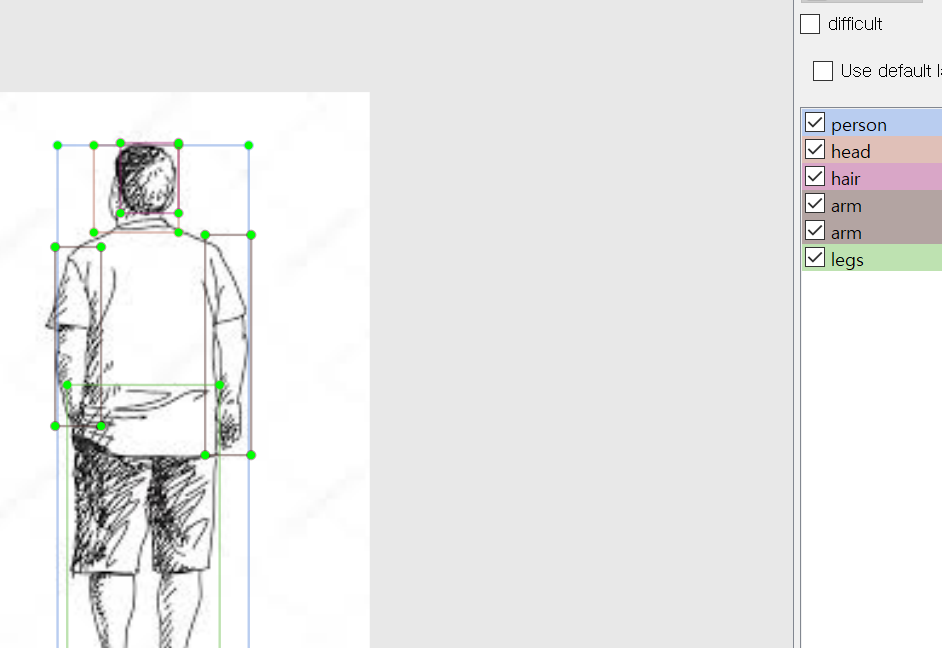
저는 라벨링을 하기전에 혹시 몰라서 auto save mode를 켜놓고 했습니다. view에서 설정할 수 있습니다.
LabelImg 사용법, 단축키
w: boundingbox 만들기, w를 누르고 마우스로 영역만큼 드래그하면 boundingbox가 만들어집니다.
box를 만들고 나면 어떤 label인지 적어주면 됩니다.
a, d: 이전 이미지 / 다음 이미지
Ctrl+d: box 복사하기
Ctrl+s: 저장하기
이렇게 라벨링을 하고 나면 각 이미지 별로 .xml 파일이 생성됩니다.

저는 약 470장의 데이터를 라벨링하는데 5시간 정도 걸린것같습니다.
2. .xml 파일 -> .csv -> TFRecord 파일로 변환하기
https://github.com/datitran/raccoon_dataset 이 깃헙 주소의 코드를 참고했습니다.
① .xml파일들 .csv파일로 변환
위의 깃헙 주소로 가면 xml_to_csv.py라는 파일이 있습니다.
이 파일의 main 부분에서는 하나의 xml파일에 대해서만 변환하도록 코딩되어있는데
저희는 폴더안의 모든 xml파일을 변환해야하므로 main 내용을 일부 수정해야합니다. (yongyong-e님 블로그 참고)
알려드린 깃헙 주소로 가셔서 xml_to_csv.py 내용을 복사한 뒤 object_detection 폴더에 같은 이름으로 파이썬 파일을 만들어주세요.
그리고 main 내용을 다음과 같이 수정해주세요.
def main(): for directory in ['train', 'test']: image_path = os.path.join(os.getcwd(), 'images/{}'.format(directory)) xml_df = xml_to_csv(image_path) xml_df.to_csv('data/{}_labels.csv'.format(directory), index=None) print('Successfully converted xml to csv.')수정을 하고 실행하면 object_detection>data폴더에 test_labels.csv, train_labels.csv 파일이 생성됩니다.
② csv 파일을 TFRecord 파일로 변환
아까와 같은 깃헙 주소로 가면 generate_tfrecord.py 파일이 있습니다.
이 파일 역시 object_detection 폴더에 내용을 복사해 파일을 만들어주세요.
그리고 class_text_to_int 의 내용을 수정해야합니다.
제가 label1, label2라고 쓴 곳에 사용할 라벨명을 적어주시면 됩니다.
혹시 라벨이 2개 이상 있으신 분들은 elif문을 똑같이 더 써주시고 return하는 int값을 다르게 작성해주시면 됩니다.
def class_text_to_int(row_label): if row_label == 'label1': return 1 elif row_label == 'label2': return 2 else: Nonecmd에서 다음과 같이 명령어를 입력해 실행해주세요
> python generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=data/train.record --image_dir=images/train
> python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=data/test.record --image_dir=images/test실행 후 data폴더에 test.record, train.record 파일이 생성된 것을 확인할 수 있습니다.

'머신러닝' 카테고리의 다른 글
[Tensorflow Object Detection API] custom data로 재학습(retraining) 시키기 3 - training (0) 2020.05.13 [Tensorflow Object Detection API] 설치하기 (for window) (0) 2020.05.06 [Tensorflow Object Detection API] custom data로 재학습(retraining) 시키기 1 - 데이터 수집 (0) 2020.05.04 TensorFlow 설치하기 (+Python설치) for Window (0) 2018.11.04